
特徴
GPUコンピューティング
GPUコンピューティングにより、効率の劣るCPUコンピューティングと比較してパフォーマンス面で大きな優位性が得られるほか、消費電力も節約できます。科学計算や工学計算の分野では、GPU革命が急速に進展しており、nanoFluidXは、この技術を利用した先駆的な商用ソフトウェアパッケージの1つとして、製品開発全体を大きく加速させようとしています。
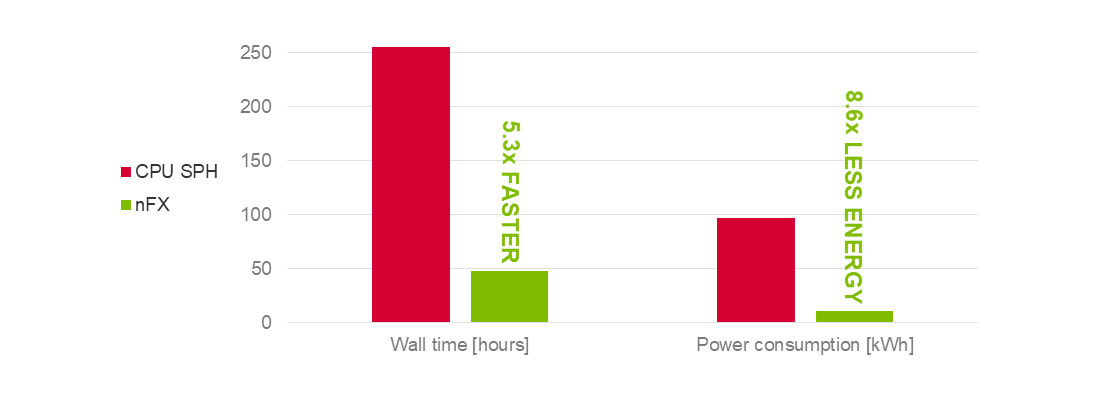
比較のため、1350万粒子からなる複雑なダブルクラッチトランスミッションの実例を用いて、3000 RPMの基準回転数と3.4秒の物理的時間におけるシミュレーションが、nanoFluidXとCPUベースの商用SPHコードで行われました。CPUコードの方は32コアのシステムを使用しましたが、nanoFluidXは、NVIDIA Tesla V100を4基搭載したシステム上で実行されました。結果として、nanoFluidXの計算時間は48時間であったのに対し、CPUコードの方は255時間でした。これは530%のスピードアップに相当し、同時に865%の省エネも達成できました。
*エネルギー消費についての仮定: 周辺機器は除く。8コアCPUの場合は95W、Tesla V100の場合は250 W
標準的な有限体積法のCFDコードを使用した場合、このように複雑なジオメトリのシミュレーションは、初期化することさえできないでしょう。仮にできたとしても、プリプロセシングに数週間もかかり、そのシミュレーションの計算コストは莫大なものになります。
下の図は、32コアのCPUシステム(Intel Xeon E5-2665)での計算と、NVIIDIA Tesla V100 GPUカード4基でのnanoFluidXの計算の比較を示します。
ハードウェア構成
nanoFluidXチームは、NVIDIA Tesla V100、P100、およびK80の各アクセラレータを推奨しています。それらはデータセンターの科学計算用として実績のあるGPUカードであり、nanoFluidXはそれらを用いて徹底的にテストされてきたからです。Nvidia Tesla Mシリーズ(M40、M60)もnanoFluidX の実行に適していますが、これらのカードは単精度でしか有意な性能を示しません。倍精度での実行は本質的に不可能です。
他のいくつかのNVIDIA GPUカード(Quadroシリーズ、GeForceシリーズ等)は、原理的にはnanoFluidXに適した計算能力を有しています。しかしながら開発チームは、これらのカード上でのnanoFluidXの精度、安定性、および全体的性能を保証していません。NVIDIAの現行の使用許諾契約(EULA)では、非Teslaシリーズのカードを4 GPU以上バンドルして、計算リソースとして商用利用することを禁止しているので注意してください。
また、このコードには最適なハードウェア使用率を保証する動的ロードバランシング機能があり、マルチノードのクラスター上でも実行できます。
推奨ハードウェア
- 64 GB以上のRAM
- CPUコア数はGPUデバイス数と同じにする必要があります。GPUデバイス間のメッセージ受け渡しはCPUによって処理されます。理想的には、結果出力等の計算オーバーヘッドをいくらか確保するために、CPUコア数は使用可能なGPUデバイス数をわずかに超えたほうがよいです。
- 2TB以上のHDD空き容量
- マルチノードシステムのためのInfinibandまたはOmniPath接続
サポートプラットフォーム
- GCC 4.4.7以降およびGLIBC 2.12を搭載した全てのUnixベースのOS(RHEL 6.xおよび7.x、互換性のあるScientific Linux、CentOS、Ubuntu 14.04および16.04、OpenSUSE 13.2など)
- NVIDIA CUDA 8.0およびOpenMPI 1.10.2 – バイナリに同梱
ギャラリー

